Der Ausgangspunkt: Vertrauen ist keine Metrik
Wenn man eine Pipeline baut, die automatisch Unternehmen recherchiert, klingt das erstmal einfach: Website scrapen, LLM drüberlaufen lassen, fertig. In der Praxis scheitert es an einer simplen Frage — woher weiß man, ob die Ergebnisse stimmen?
Deshalb haben wir rückwärts angefangen. Bevor eine einzige Zeile Pipeline-Code geschrieben wurde, haben wir Ground Truth gebaut: Unternehmen manuell recherchiert, jedes einzelne Feld von Hand verifiziert — Produkte, Kunden, Zertifizierungen, Kontakte, Finanzdaten.
8 Module, 3 Methoden
Das Ergebnis ist eine modulare Pipeline aus 8 Stufen:
- Module 1–6 sammeln Daten: Website-Analyse, Finanzberichte, Kontaktsuche, Informationsextraktion, statische Methoden und externe Datenbanken
- Modul 7 bewertet die Qualität der gesammelten Daten über 5 Dimensionen
- Modul 8 bewertet die geschäftliche Relevanz — unabhängig von der Datenqualität
Nicht jedes Modul braucht ein LLM. Drei verschiedene Ansätze kommen zum Einsatz: regelbasierte Heuristiken, statische Methoden und LLM-basierte Extraktion.
Die Metriken
Die überraschendsten Erkenntnisse kamen nicht vom LLM, sondern von den Zahlen:
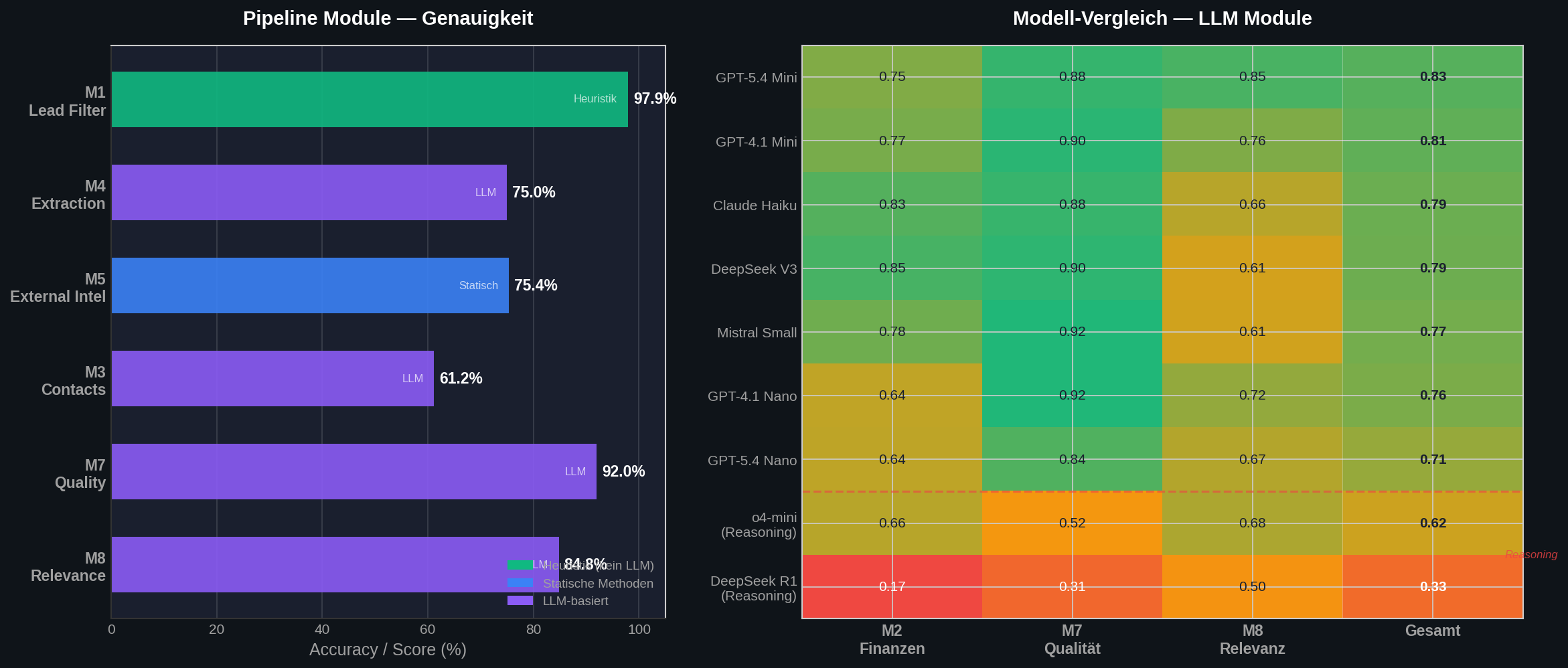
- Modul 1: 97,9 % Genauigkeit — komplett ohne KI. Einfache Heuristiken reichen, um zu erkennen, ob ein Unternehmen als Lead in Frage kommt. Über 70 % der zufälligen Handelsregister-Einträge fallen sofort raus: Vereine, Briefkastenfirmen, aufgelöste GmbHs.
- Modul 4: 98 % True Precision bei 61 % Recall (F1 = 0,75). Was die Pipeline findet, stimmt fast immer. Sie findet nur noch nicht alles.
- Modul 5: 75,4 % Genauigkeit mit rein statischen Methoden — kein LLM nötig.
- Modul 7: bis zu 92 % Score bei der automatischen Qualitätsbewertung.
Reasoning-Modelle: Mehr Denken, schlechtere Ergebnisse
Der kontraintuitivste Befund betrifft die Modellwahl. Wir haben klassische Instruction-Modelle gegen Reasoning-Modelle getestet — also Modelle, die explizit "nachdenken", bevor sie antworten.
Das Ergebnis: Reasoning-Modelle performen bei strukturierter Extraktion deutlich schlechter. DeepSeek R1 landet mit einem Durchschnitt von 0,33 auf dem letzten Platz. OpenAIs o4-mini kommt auf 0,62 — ebenfalls unter den einfachen Instruction-Modellen.
Die Hypothese: Reasoning-Modelle sind optimiert für logische Schlussfolgerungen und mehrstufige Argumentation. Bei der Aufgabe "lies eine Website und extrahiere strukturierte Fakten" bringt das keinen Vorteil — im Gegenteil, es führt zu Overthinking und schlechteren JSON-Strukturen.
Der Schlüssel
Die wichtigste Erkenntnis aus diesem Projekt ist keine technische: Der Schlüssel war nicht das Modell. Der Schlüssel war die Ground Truth.
Ohne manuell verifizierte Referenzdaten wüssten wir nicht, ob unsere Pipeline 98 % oder 48 % Precision hat. Wir würden Outputs lesen, die "plausibel aussehen", und hoffen, dass sie stimmen. Ground Truth macht den Unterschied zwischen Hoffnung und Wissen.