Das Problem: Eine Pipeline ohne Feedback-Schleife
Unsere Content-Pipeline kann aus einem Thema automatisch Blog-Artikel, LinkedIn-Posts und Bilder generieren. Ein API-Call. Fertig. Aber "fertig" heißt nicht "gut".
Wer Inhalte produziert, steht vor der gleichen Frage wie jeder genetische Algorithmus: Welche Individuen überleben? Welche Story-Typen erzeugen Reichweite? Welche Hooks funktionieren? Welcher Kanal bringt Traffic zurück auf die Website?
Ohne Messung ist das Raten. Und Raten skaliert nicht.
In der biologischen Evolution entscheidet die Umwelt, was überlebt. In der Content-Evolution entscheidet der Leser — aber nur, wenn man ihn messen kann.
Warum keine externe Abhängigkeit
Die naheliegende Lösung wäre ein Drittanbieter-Tool. Das Problem: Jede externe Abhängigkeit ist ein Kontrollverlust. Die Daten liegen auf fremden Servern, das Schema ist vorgegeben, die Aggregation folgt fremder Logik. Wenn sich die API ändert oder der Anbieter die Preise erhöht, bricht die Feedback-Schleife.
Für eine autonome Content-Pipeline ist das inakzeptabel. Die Fitness-Funktion muss genauso unter eigener Kontrolle stehen wie die Pipeline selbst. Eigene Datenbank, eigenes Schema, eigene Auswertung — kein Vendor Lock-in, kein Consent-Banner, keine JavaScript-Abhängigkeit im Frontend.
Die Fitness-Funktion: Sechs Signale
Biologische Fitness misst Reproduktionserfolg. Content-Fitness misst Resonanz. Unser System erfasst sechs Signale:
- Seitenaufrufe pro Pfad — welche Themen ziehen
- Referrer-Quellen — LinkedIn, Google, Direktzugriff — welcher Kanal konvertiert
- Geräteverteilung — Desktop vs. Mobile zeigt, wo und wann gelesen wird
- Browser und OS — technische Reichweite der Zielgruppe
- Unique Visitors — Reichweite pro Tag über tagesrotierende IP-Hashes
- Zeitverlauf — Tagesserien zeigen, ob ein Thema nachhaltig Traffic bringt oder nur einen Spike erzeugt
Das reicht, um die entscheidende Frage zu beantworten: Welche Stories performen — und warum?
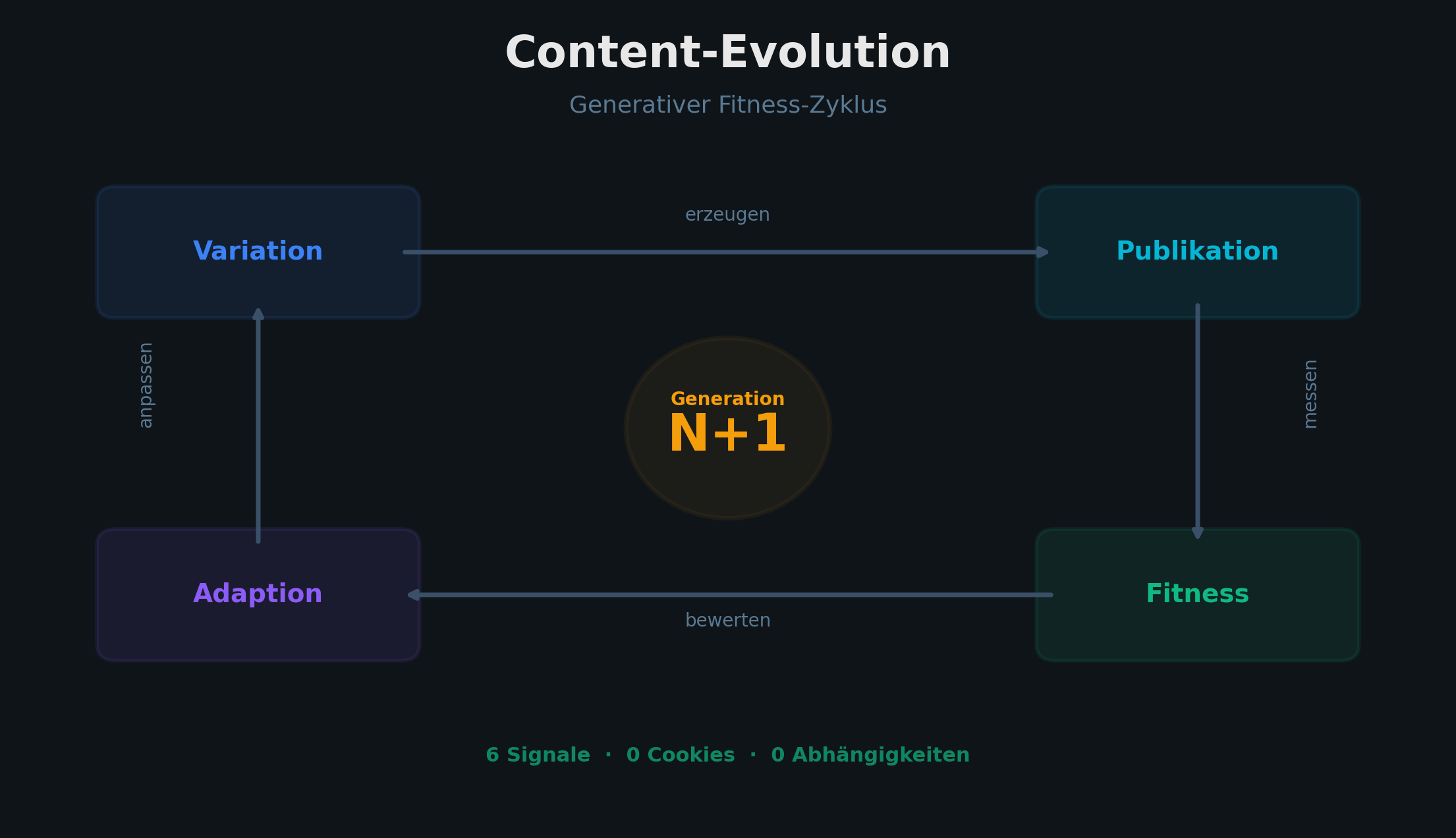
Selection Pressure: Vom Signal zur Entscheidung
Die Parallele zur Genetik ist kein Marketing-Trick. Sie ist architektonisch:
Variation — die Content-Pipeline produziert Stories in fünf Typen (Feature, Concept, Metric, Showcase, Behind the Scenes) mit unterschiedlichen Hooks, Längen und Kanälen.
Selektion — das Analytics-System misst, welche Kombinationen Fitness erzeugen. Ein Metric-Artikel mit Zahlentitel und LinkedIn-Referrer? Hohe Fitness. Ein Behind-the-Scenes ohne klaren Hook? Niedrige Fitness.
Adaption — die Erkenntnisse fließen zurück in die Pipeline. Story-Typ-Verteilung, Hook-Muster, Kanal-Priorisierung — alles steuerbar über die gemessene Fitness.
Ohne Fitness-Funktion optimiert man ins Leere. Die Pipeline produziert — aber sie lernt nicht.
Architektur: Zwei Tabellen, kein Overhead
Die technische Umsetzung ist bewusst minimal. Zwei Tabellen in der bestehenden MariaDB:
page_views speichert jeden Seitenaufruf — Pfad, Referrer-Domain, Gerätetyp, Browser, Bildschirmbreite, gehashte IP. daily_page_stats aggregiert Tageswerte vor — Views, Unique Visitors, Device-Breakdown pro Seite.
Serverseitig erfasst. Kein Client-JavaScript, kein Cookie, kein externer Request. Die IP wird mit einem täglich rotierenden SHA256-Salt gehasht — Unique-Counting ohne Wiedererkennung. DSGVO-konform ohne Consent-Banner, weil es nichts gibt, wozu man einwilligen müsste.
Sechs API-Endpoints liefern die Daten ans Dashboard: Übersicht, Seiten-Performance, Referrer-Ranking, Zeitserien, Browser-Verteilung, Live-Stream. Vom leeren Schema zum funktionierenden Dashboard — ein Tag.
Der Tradeoff ist Feature, kein Bug
Wir können keine User Journeys nachvollziehen. Keine Scroll-Tiefe messen. Keinen Funnel bauen. Das ist Absicht. Eine Fitness-Funktion muss das Richtige messen — nicht alles.
Biologische Fitness ist auch nicht "wie viele Schritte hat das Tier heute gemacht". Sie ist: Hat es sich reproduziert? Unsere Content-Fitness ist: Hat der Artikel Leser angezogen, die wiederkommen?
Sechs Signale. Null Abhängigkeiten. Eine geschlossene Feedback-Schleife.


